Data Pre-Proccessing CLI
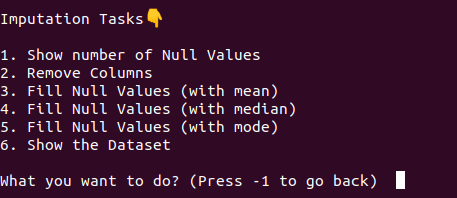 CLI Screen
CLI Screen
The CLI was developed for efficient data preprocessing, crucial in refining raw data for analytical tasks. Through a user-friendly command-line tool, it streamlines tasks such as cleaning, encoding, and visualization, thereby empowering data scientists to optimize workflows and ensure data integrity. Key functionalities include handling missing data, resolving inconsistencies, and selecting relevant features, all aimed at enhancing data quality and improving machine learning model performance. The framework utilizes a customer dataset from a credit card company, focusing on preprocessing techniques tailored for predictive modeling.
By addressing challenges like class imbalance and inconsistencies within variables like salary, the project employs command-line tools for data manipulation and resampling. The seamless integration of preprocessing steps into the modeling pipeline enhances reproducibility, automation, and scalability, facilitating the development of robust models capable of predicting customer purchase behavior effectively.
Nitish Ramaraj
Computer Science Graduate Student
Gradute computer science student passionate about NLP and Systems.